当ブログ内では, 既に確率論の話題としてベイズの定理のエントリが存在するが, 今後同様にして確率論の話題を本ブログで取り上げる際に, 用語へのリファレンスを self-contained で張れるよう, 本エントリにて一度整理しておくこととした\(.\)
確率の定義
そもそも一言に「確率」といえども, それは古典的確率, 統計的確率, 公理的確率というように大別できる.
古典的確率
古典的確率は, \(\Omega\) の要素数といま注目している事象の場合の数の比を用いるもので, すべての事象が等確率で発生することを前提条件とする. 理想的なサイコロの出目の確率などがこれに当てはまる.
統計的確率
統計的確率は, 「\(\Omega\) の部分集合 = 事象」の発生回数と, その試行回数の比を用いるもので, 打率などがこれに当てはまる.
公理的確率
公理的確率とは, 確率の公理により定義された確率であり, 同公理における理論体系上では各事象の発生する確率が異なるものをも扱うことができる. この確率の公理では集合論, 測度論の言葉が使われるが, 同理論に関して深堀りすると本エントリの主題から大きく逸れてしまうため, ここではあまり深くは触れずに持ち出すこととしている.
集合のあつまりを一般に集合族というが, 次に示すのはその 1 種である1.
- \(\emptyset\in \mathcal{F}\)
- \(A\in\mathcal{F}\Rightarrow A^{c}\in\mathcal{F}\)
- \(\displaystyle A_1,A_2,\cdots\in\mathcal{F}\Rightarrow \bigcup^{\infty}_{i=1}A_i \in\mathcal{F}\)
\(\sigma\)-加法族は, 空集合と補集合, 加算無限個の集合の和集合について閉じることを要請し, 確率の公理は, この \(\sigma\)-加法族の関数に対して次の条件を付与する.
- \(0\leq P(A)\leq 1,\ ^\forall A\in\mathcal{F}\)
- \(P(\Omega) = 1\)
- \(A_1,A_2,\cdots\in\mathcal{F}\) があって, \(\displaystyle \bigcap^{\infty}_{i=1}A_i = \emptyset\)(互いに排反) \(\displaystyle\Rightarrow P\left(\bigcup_{i=1}^\infty A_i\right)=\sum_{i=1}^\infty P(A_i)\)
可算無限個の事象が互いに排反な事象の和集合の値は, 各事象の値の和となる.
なお, 標本空間を \(\Omega =\left\{x_1,x_2,\cdots,x_n\right\}\), \(p_1,\dots,p_n\) がそれぞれ \(\displaystyle 0\leq p_{i}\leq 1\) で, \(\displaystyle \sum_{i=1}^{n}p_{i}=1\) であるとき, \(\Omega\) の部分集合 \(A\) に対して関数 \(P\) を \(P(A)=\displaystyle\sum_{\left\{i\ |\ x_i\in A\right\}}p_i\) とすると \(P\) は確率関数となるから, 統計的確率論の問題は公理的確率論の問題として扱うことができるといえ, 自ずと公理的確率論が統計的確率論の拡張であることがいえる.
基本的な言葉
| 用語 | 意味 | 表現 |
|---|---|---|
| 標本空間 | 試行に付随して決まる, 試行の取りうるすべての結果から成る \(\emptyset\) でない集合. | \(\Omega\) |
| 標本 | 標本空間の元. 試行の結果発生しうる個々の事柄. | \(\omega\in\Omega\) |
| 事象 | 標本空間の部分集合. 試行の結果発生しうる事柄. | \(A\subset\Omega\) |
| 確率変数 | ある事象が確率的に取りうる数.
|
\(X\) |
| 実現値 | 確率変数がとる具体的な値. | \(x_n\) |
| 確率分布 | 確率変数がある値となる確率, 又はある集合に属する確率を与える関数(JIS 規格より). | \(P(A)\) |
| 「独立同一分布に従う」 |
確率変数 \(X_1,X_2,\cdots,X_n\) が互いに独立で, かつそれらが同一の確率分布に従うことをいう.
|
\(\rm i.i.d\), independent and identically distributed. |
全体の総和をそれらの個数で割った値. \(\displaystyle\dfrac{1}{n}\sum^{n}_{i=1}X_i\). |
|
|
| 期待値 |
確率変数のとりうる値にそれが起こる確率を掛けた値の総和のこと(加重平均).
すなわち, 確率変数 \(X\) の取り得る値 \(x\) に関する確率 \(P(x_i)\) があって,
\begin{cases}
\displaystyle\sum^{n}_{i=1}x_i P(x_i) &:X {\rm は離散的確率変数}\\
\displaystyle\int^\infty_{-\infty} xP(x)dx &:X {\rm は連続的確率変数}
\end{cases}
|
|
| 条件付き確率 |
ある事象が起きる条件のもとで, 別のある事象が起こる確率.
\[P\left(A\mid B\right)=\dfrac{P\left(A\cap B\right)}{P\left(B\right)}\ \left(\because P\left(A\cap B\right):=A\ {\rm および}\ B\ {\rm が発生する確率}\right)\]
|
\(B\) の下で \(A\) が発生する確率: \(P\left(A\mid B\right)\) |
| 条件付き期待値 |
確率変数 \(X\) の値が \(x\) であるときの \(Y\) の期待値. \(E\left[Y|X=x\right]\)
\[E\left[Y|X=x\right]=\sum^{n}_{i=1}y_i\dfrac{P\left(Y=y_i,X=x\right)}{P\left(X=x\right)}\]
|
\(E\left[Y|X\right],\ E_Y\left[Y|X\right]\) |
| 条件付き分散 |
\(V[X\mid Y]=E[X^2\mid Y]-E[X\mid Y]^2\)
|
\(V\left[Y|X\right],\ V_Y\left[Y|X\right]\) |
|
ある関数が規格化条件を満足するように定数倍すること. 平均を引いて, 標準偏差で割る(\(\dfrac{X-\mu}{\sigma}\))5こと.
|
N/A |
|
期待値とのずれを表す指標の 1 つ. ずれの総計で各々が相殺しないように二乗和をとり, その個数 \(n\) で割った値. すなわち,
\[\dfrac{1}{n}\displaystyle\sum_{i=1}^n(X_i-E\left[X\right])^2=E\left[(X-E\left[X\right])^2\right]\]
|
|
|
標本数 \(n\) で割ったのに対し, \(n-1\) で割った値. 標本分散の期待値が母分散に等しくなるように補正したもの (詳細は下記): \(\displaystyle\dfrac{1}{n-1}\sum^n_{i=1}\left(X_i-E\left[X\right]\right)^2\) | \(U^2,\hat{\sigma}^2\) |
| 標準偏差 | 分散の計算で行われた二乗を外した形. | \(\sqrt{V[X]},\sigma,s\). 各記号は, 分散の記号と同様にして用いられる慣習がある. |
不偏分散
上記の表で示した通り, 不偏分散は, 標本分散の期待値が母分散に等しくなるように補正したもののことをいう. 標本分散は, 標本のばらつきの指標を得ることが主な目的であったのに対して, 不偏分散は, 標本から母分散の推定値を得ることが主な目的であり, その点において両者は異なる. その目的に従って, 標本分散の期待値 \(E\left[s^2\right]\) は, 母分散の \(\dfrac{n-1}{n}\) 倍となっているという事実(\(E\left[s^2\right]=\dfrac{n-1}{n}\sigma^2\not =\sigma^2\))から, 標本分散を \(\dfrac{n}{n-1}\) 倍する(しかしながら, サンプル数 \(n\) が十分に大きいとき, 両者は近似的に等しくなることが大数の弱法則よりいえる). この形が不偏分散である.
以下, \(E\left[s^2\right]=\dfrac{n-1}{n}\sigma^2\) を証明する.
証明:
いま \(\rm i.i.d\) 標本 \(X_1,X_2,\cdots,X_n\) について考えると, この標本分散は上記の表で示した通り \(\displaystyle s^2=\overline{X^2}-\overline{X}^2=\dfrac{1}{n}\sum^{n}_{i=1}\left(X_i-\overline{X}\right)^2\) で, 母分散は \(\sigma^2=E\left[\left(X-\mu\right)^2\right]\) である. ここで, \(X_i-\overline{X}=X_i-\mu-\overline{X}+\mu\) とおくと,
である. この期待値は
で, \(\eqref{eq:second}\) の第二項は標本平均分散だから,
\(\square\)
正規分布, ガウス分布
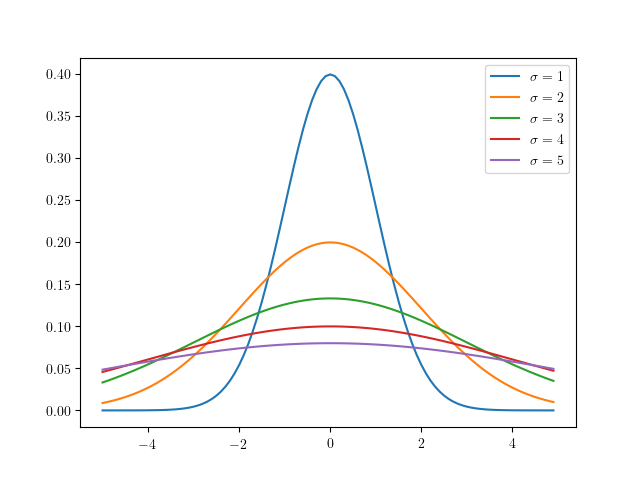
上図7のような, 連続型の確率分布が左右対称である分布を正規分布といい, その陰関数は \(f(x)=\dfrac{1}{\sqrt{2\pi}}\exp\left(-\dfrac{1}{2}\left(\dfrac{x-\mu}{\sigma}\right)^2\right)\) であり, これを \(N(\mu,\sigma)\) とも書く. また, その確率密度関数は
である.
また \(\mu=0,\sigma=1\) である正規分布をとくに標準正規分布といい(上図青で描かれた分布がそれに該当する), その場合の陰関数は \(f(x)=\dfrac{1}{\sqrt{2\pi}}\exp\left(-\dfrac{1}{2}x^2\right)\) となる. また, これを \(N(\mu,\sigma)=N(0,1)\) とも書く. ここで一度, 式 \(\eqref{eq:first}\) が規格化条件を満たすことを確認する. 確認には, ガウス積分の公式を用いる.
命題: \(\eqref{eq:first}\) は規格化条件を満たす.
証明: \(\eqref{eq:first}\) が規格化条件を満たすことは次の等号式を満たすことである.
\[\displaystyle\int_{-\infty}^{\infty}f(x)dx=\dfrac{1}{\sqrt{2\pi}\sigma}\int_{-\infty}^{\infty}\exp\left(-\dfrac{(x-\mu)^2}{2\sigma^2}\right)dx\]
ここで, \(x-\mu=y\) と変数変換すると \[\dfrac{1}{\sqrt{2\pi}\sigma}\int_{-\infty}^{\infty}\exp\left(-\dfrac{y^2}{2\sigma^2}\right)dy\] この積分部分はガウス積分の公式より, \(\sqrt{2\sigma^2\pi}\) となり \(f(x)\) を全区間で積分すると 1 となる. よって, \(\eqref{eq:first}\) は規格化条件を満たす. \(\square\)
正規分布においては, 区間 \([-\sigma,\sigma]\) を 1 シグマ区間という. 平均 \(\pm{1\sigma}\) 内に収まる確率は \(68\) %, 平均 \(\pm{2\sigma}\) 内に収まる確率は \(95\) %, 平均 \(\pm{3\sigma}\) 内に収まる確率は \(99.7\) % であると知られている.
大数の法則
大数の法則は,
である. なお, この法則を確率論の用語で, \(\overline{X}_n\) が \(\mu\) に確率収束するという. 端折って解釈すると, ある母集団から無作為抽出するサンプル数を十分に大きくしたとき, それらから成る標本の平均は, 母平均そのものとみなしてもよいという主張である. 例えば, サイコロの目の理論的な平均値は \(\frac{\sum^{6}_{i=1} i}{6}=3.5\) であるが, サイコロを例えば 2 回降っただけではこの通りの平均値にならないかもしれない. しかしながら, これを無限回行えば, その平均は \(3.5\) に限りなく近くということである. ここでは簡単のために大数の弱法則についてのみの証明とする. そのために, まずマルコフの不等式, チェビシェフの不等式の証明を行う.
証明:
\(X\) を連続型確率変数とすると, 確率密度関数 \(f_X(x)\) に対して,
\(\therefore P\left(\left|X\right|\geq c\right)\leq\dfrac{E[\left|X\right|]}{c}\). \(X\) が離散型確率変数である場合は総計により同様にして求まる. \(\square\)
証明:
マルコフの不等式より, \(X=(Y-\mu)^2,c=a^2\sigma^2\) とすると
\(\therefore P\left(\left|Y-\mu\right|\geq a\sigma\right)\leq\dfrac{1}{a^2}\). \(c=a^2\) とすると, 同様にして \(P\left(\left|Y-\mu\right|\geq a\right)\leq\dfrac{\sigma^2}{a^2}\). \(\square\)
準備が整ったので, 以下大数の弱法則を証明する.
証明:
確率変数 \(\overline{Y}\) を \(\rm i.i.d\) 標本平均 \(\displaystyle\dfrac{1}{n}\sum_{i=1}^{n}Y_i\) とすると, 期待値の線型性より \(E\left[\overline{Y}\right]=\mu,V\left[\overline{Y}\right]=\dfrac{\sigma^2}{n}\). ここで, チェビシェフの不等式より \(P\left(\left|\overline{Y}-\mu\right|\geq a\right)\leq\dfrac{\dfrac{\sigma^2}{n}}{a^2}\) だから, \(n\to\infty\) のとき, 右辺は \(0\) に収束する. \(\square\)
中心極限定理
中心極限定理は
という定理である. 大数の弱法則とこの中心極限定理ともにサンプル平均 \(\overline{X}_n\) の振る舞いに関する定理であるが, 後者においては, サンプル平均と, 真の平均との誤差について論ずる定理である点が異なる. つまり, 大数の弱法則より \(\overline{X}_n\approx\mu\) であることはわかったが, その差 \(\overline{X}_n-\mu\) はどのような挙動となるのか, また \(0\) に近づいていくのはわかったが, どのように近づいていくのかについて論じているのが, 中心極限定理である8. 中心極限定理は, それが正規分布に近似するといっているので, 起きた事象の珍しさを測るための指標として用いることができ, これが統計における検定に役立つ. また, すべての平均と分散が定義できるような分布9に対していえることから, 様々な事象が正規分布に従うことを正当化するための理論的根拠としてよく用いられる.
参考文献
- 「第 2 章 独立確率変数列の極限定理」 2018 年 10 月 29 日アクセス.
- 「コーシー分布」 2018 年 10 月 29 日アクセス.
- 「正規分布の基礎的な知識まとめ - 高校数学の美しい物語」 2018 年 9 月 27 日アクセス.
- 「大数の法則と中心極限定理の意味と関係 - 高校数学の美しい物語」 2018 年 10 月 29 日アクセス.
- 「条件付き期待値,分散の意味と有名公式 - 高校数学の美しい物語」 2018 年 11 月 12 日アクセス.
- 「3.3 条件付き期待値」 2018 年 11 月 12 日アクセス.
-
\(\sigma\)-加法族は, 完全加法族, 可算加法族, \(\sigma\)-集合代数, \(\sigma\)-集合体ともいわれる. ↩
-
簡単のため, 確率変数 \(X, Y\) に対して \(E\left[X,Y\right]=E\left[X\right]+E\left[Y\right]\) を示して証明とする. ここで, \(\sum_i:=\sum^n_{i=1},\sum_j:=\sum^n_{j=1}\) とし, 確率変数 \(X\) がその取り得る値 \(x_i\) となる確率を \(P(x_i)\), 同様に \(Y\) がその取り得る値 \(y_j\) となる確率を \(P(y_j)\) とする. また, そのどちらもが同時に発生する確率を \(P(x_i,y_j)\) とする.
\begin{eqnarray} E\left[X+Y\right]&=&\sum_i\sum_j\left(x_i+y_j\right)P(x_i,y_j) \\\ &=&\sum_i\sum_j x_iP(x_i,y_j)+\sum_i\sum_j y_jP(x_i,y_j) \\\ &=&\sum_i x_i\sum_j P(x_i,y_j)+\sum_j y_j\sum_i P(x_i,y_j) \\\ &=&\sum_i x_iP(x_i)\sum_j y_jP(y_j) \\\ &=& E\left[X\right]+E\left[Y\right] \end{eqnarray}連続的確率変数に対しても, 積分の線型性から同様. \(\square\) ↩ -
\(\eqref{eq:exaxiom3}\) および期待値の線形性より
\begin{eqnarray}E\left[\overline{X}\right]&=&E\left[\dfrac{1}{n}\sum^n_{i=1}X_i\right] \\\ &=&\dfrac{1}{n}E\left[X_1+\cdots+X_n\right] \\\ &=&\dfrac{1}{n}n\mu \\\ &=&\mu \end{eqnarray}\(\square\) ↩ -
簡単のため, 連続型確率変数 \(X,Y\) に対する \(E\left[Y\right]=E\left[E\left[Y|X\right]\right]\) を示して証明とする. \(E\left[Y\right]\) は条件付き期待値の定義から
$$E\left[Y\right]=\int^\infty_{-\infty}\int^\infty_{-\infty}yf(x,y)dxdy$$ここで, \(f(x,y)\) は \(X,Y\) の同時確率密度関数である. 従って,\begin{eqnarray}E\left[Y\right]&=&\int^\infty_{-\infty}\int^\infty_{-\infty}yf(x,y)dxdy \\\ &=&\int^\infty_{-\infty}\int^\infty_{-\infty}y\dfrac{f(x,y)}{f(x)}f(x)dxdy \\\ &=&\int^\infty_{-\infty}\left[\int^\infty_{-\infty}yf(y|x)dx\right]f(x)dx \\\ &=& \int^\infty_{-\infty}E\left[X|y\right]f(x)dydx \\\ &=&E\left[E\left[Y|X\right]\right]\end{eqnarray}\(\square\) ↩ -
平均 \(\mu\), 分散 \(\sigma^2\) の確率変数 \(X\) を正則化した変数 \(Z=\dfrac{X-\mu}{\sigma}\) の期待値と分散を確認してみると, 平均は \(\eqref{eq:exaxiom2}, \eqref{eq:exaxiom3}\) より
\begin{eqnarray}E\left[Z\right]&=&E\left[\dfrac{X-\mu}{\sigma}\right] \\\ &=&\dfrac{1}{\sigma}E\left[X-\mu\right] \\\ &=& \dfrac{1}{\sigma}\left(E\left[X\right]-\mu\right) \\\ &=&\dfrac{1}{\sigma}\left(\mu-\mu\right) \\\ &=&0\end{eqnarray}分散は \(\eqref{eq:exaxiom6}, \eqref{eq:exaxiom7}\) より\begin{eqnarray}V\left[Z\right]&=&V\left[\dfrac{X-\mu}{\sigma}\right] \\\ &=&\dfrac{1}{\sigma^2}V\left[X-\mu\right] \\\ &=&\dfrac{1}{\sigma^2}V\left[X\right] \\\ &=&\dfrac{\sigma^2}{\sigma^2} \\\ &=& 1\end{eqnarray}となり標準正規分布に従うことがわかる. ↩ -
\(\eqref{eq:exaxiom7}\) および期待値の線形性より
\begin{eqnarray}V\left[\overline{X}\right]&=&V\left[\dfrac{1}{n}\sum^n_{i=1}X_i\right] \\\ &=&\dfrac{1}{n^2}V\left[X_1+\cdots+X_n\right] \\\ &=&\dfrac{1}{n^2}n\sigma^2 \\\ &=&\dfrac{\sigma^2}{n}\end{eqnarray}\(\square\) ↩ -
参考文献から一部引用: ベーシックな大数の弱法則は中心極限定理から導出することができます。→The Laws of Large Numbers Compared(snip) しかし,より一般的な(仮定を弱めた)大数の弱法則は中心極限定理から導出することはできません。つまり「中心極限定理が大数の法則を包含している」と言うことはできないのです。 ↩
-
平均, 分散が定義できない分布の例としてよく挙げられるものの 1 つ: コーシー分布. ↩