大学のレポート内で De Bruijn Sequence について書く機会があった. これまた以前と同じく, 折角なのでこちらのブログにも, 若干内容を変えつつ載せておくことにした.
De Bruijn Sequence は, オランダ人の数学者 Nicolaas de Bruijn に因んで命名された系列で, 特定の長さのすべての組み合わせを含む系列である. 次数 \(n\) の \(k\) 種類に関する De Bruijn Sequence \(B\left(k, n\right)\) は, 長さ \(n\) で表現可能なすべての部分列によって構成される. 次元数 \(2\) (すなわちバイナリ) の De Bruijn Sequence は \(B\left(2, n\right)\) であり, \(n\) ビットの固有な部分系列から成る \(2^n\) ビット長の系列である. 例えば, \(B\left(2, 3\right)\) は \(00011101_{(2)}\) であり \(n\) に対する有向グラフが下図1のように示される.
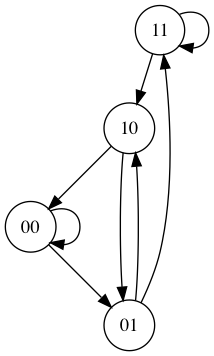
この系列から \(3\) ビットずつ取る, または図 1 の有向グラフから \(B(2, 3)\) を再構築していくと, 次の表で示す部分系列を構成することがわかる.
| \[B(2,3)\] | \[10\ {\rm進値}\] |
|---|---|
| \[\overbrace{000}^{sub\ seq}11101_{(2)}\] | \[0_{(10)}\] |
| \[0\overbrace{001}^{sub\ seq}1101_{(2)}\] | \[1_{(10)}\] |
| \[00\overbrace{011}^{sub\ seq}101_{(2)}\] | \[3_{(10)}\] |
| \[000\overbrace{111}^{sub\ seq}01_{(2)}\] | \[7_{(10)}\] |
| \[0001\overbrace{110}^{sub\ seq}1_{(2)}\] | \[6_{(10)}\] |
| \[{00011\overbrace{101}^{sub\ seq}}_{(2)}\] | \[5_{(10)}\] |
| \[{000111\overbrace{01\underbrace{0}_{cir}}^{sub\ seq}}_{(2)}\] | \[2_{(10)}\] |
| \[{0001110\overbrace{1\underbrace{00}_{cir}}^{sub\ seq}}_{(2)}\] | \[4_{(10)}\] |
最後の \(2\) つの部分系列は \(00011101_{(2)}\) から \(3\) ビットずつとって構成できないが, 系列の初めへ循環していると考えることで, これが成り立つ.
De Bruijn Sequence は, いくつかのコンピュータアルゴリズムで応用でき, 例えば Number of Training Zero を求める問題も, よく知られた応用例の 1 つである. これは ntz と呼ばれる. 以降, \(m=n-1\), \(x\) を \(8\) ビットの値, \(x_i\ \ \left(\left\{i \in \mathbb{Z}\mid 0 < i < 9\right\}\right)\) を lsb 見た値 \(x\) の \(i\) 番目のビット値, Number of Training Zero を ntz とする.
例えば \(x=192_{(10)}\) は
であり, \(m=6\) が解である.
ntz をプログラムで解こうとしたとき, 例えば次のような実装がよく知られる.
module Main where
import Control.Monad (void)
import Data.Bits ((.&.), shiftR)
import Data.Word (Word8)
import Data.Tuple.Extra (first, second, dupe)
import Test.HUnit (runTestText, putTextToHandle, Test (TestList), (~:), (~?=))
import System.IO (stderr)
-- | pop counting 8 bit
popcnt8 :: Word8 -> Word8
popcnt8 = let fol m s = uncurry (+) . first (.&. m) . second ((.&. m) . (`shiftR` s)) . dupe in
flip (foldr id) [fol (0x0f :: Word8) 4, fol (0x33 :: Word8) 2, fol (0x55 :: Word8) 1]
-- | ntz 8 bit version 1
ntz81 :: Word8 -> Word8
ntz81 = uncurry id . first (bool (popcnt8 . pred . uncurry (.&.) . second negate . dupe) (\_ -> 8 :: Word8) . (== 0)) . dupe
main :: IO ()
main = void . runTestText (putTextToHandle stderr False) $ TestList ["ntz81 192: " ~: ntz81 (192 :: Word8) ~?= 6]
popcnt8は, 各ビットそのものがその桁で立っているビット数と捉え, 畳み込んでいくことで最終的に立っている全体のビット数を得る関数である.
ntz81 は, まず lsb から見て一番端で立っているビットを倒し, それまでのビット列を全て立てておく. これをpopcnt8に渡すことで ntz としての役割を果せる.
これはとても有名な方法で, よく最適化された手法であるといえるのだが, De Bruijn Sequence を利用すると, より少ない演算回数で ntz が解ける.
De Bruijn Sequence を利用して ntz を解く方法は, 随分前にこのブログさんで丁寧に解説されているので,
特別ここで改めて詳しく述べる必要はないとは思うが, 一応レポート内で書いた内容を載せておく.
- \(B(2, n)\) から成る部分系列を元とした集合 \(X\) と, 「系列全体からみて, その部分系列を得るにいくつスライドしたか」を元とする集合 \(Y\) の写像 \(f\) を定める(例: \(f(000_{(2)}) = 0, f(001_{(2)}) = 1, f(011_{(2)}) = 2, \cdots f(100_{(2)}) = 7\)).
- \(x\) のうち一番右端に立っているビットのみを残し, 他を全て倒す(
x & -x). この値は必ず \(2^i\) である. これを \(y\) とする. - \(B(2, n)\) と \(y\) の積を得る(\(y = 2^i\) であるから, この演算は系列に対する \(i\) ビットの左シフト演算である). これを \(z_0\) とする.
- いま, ここまでの演算を \(s\ (\{s \in \mathbb{Z}\mid s > n, s は 2 の累乗数\})\) ビットの領域上で行なったとしたとき, \(z_0\) に対して \(s-n\) ビット左にシフトする(\(z_0\) を msb から数えて \(n\) ビット分のみが必要であるから, それ以外を除去する). これを \(z_1\) とする.
- \(f(z_1)\) の値が ntz の解である.
要するに, De Bruijn Sequence の特徴を生かして, ユニークなビット列に紐づく各値をマッピングしておき, 積がシフト演算と同等となるように調節, いらない値を省いた後にテーブルを引くのである2.
module Main where
import Data.Array (Array, listArray, (!), elems)
import Data.Tuple.Extra (dupe, first)
import Data.Bits ((.&.), shiftR)
import Data.Word (Word8)
import Test.HUnit (runTestText, putTextToHandle, Test (TestList), (~:), (~?=))
import System.IO (stderr)
import Control.Monad (void)
-- | ntz 8 bit version 2
ntz82 :: Word8 -> Word8
ntz82 = (tb !) . (`shiftR` 4) . fromIntegral . ((0x1d :: Word8) *) . uncurry (.&.) . first negate . dupe
where
tb = listArray (0, 14) [8, 0, 0, 1, 6, 0, 0, 2, 7, 0, 5, 0, 0, 4, 3] :: Array Int Word8
main :: IO ()
main = void . runTestText (putTextToHandle stderr False) $ TestList ["192 ntz: " ~: ntz82 (192 :: Word8) ~?= 6]
ここまでは \(x\) が \(8\) ビットである前提を置いて述べてきたが, 任意の \(B(2, n)\) が求まれば, どのようなビット長のデータに対しても同様にして計算できることがわかる. これをどのように得るかであるが, ここでは Prefer One algorithm3 という比較的単純なアルゴリズムを用いて \(B(2, n)\) を得ることとする. このアルゴリズムに関する詳細と証明は原文を読んでほしいが, その大雑把な概要だけをここでは述べる. 任意の正整数 \(n\geq 1\) について, まず \(n\) 個の \(0\) を置く. 次に, 最後の \(n\) ビットによって形成された部分系列が以前に系列内で生成されていなかった場合, その次のビットに対して \(1\) を, そうでない場合 \(0\) を置く. \(0\) または \(1\) のどちらを置いても, 以前に生成していた部分系列と一致するならば停止する. 下記に示す同アルゴリズムの実装例は, \(2^3\) から \(2^6\) に対応する De Bruijn Sequence を得ている.
module Main where
import Data.Array (listArray, (!))
import Data.Tuple.Extra (dupe, first)
import Control.Monad (mapM_)
import Numeric (showHex)
preferOne :: Int -> [Int]
preferOne n = let s = 2 ^ n in
let ar = listArray (1, s) $ replicate n False ++ map (not . yet) [n + 1 .. s]
yet i = or [map (ar !) [i - n + 1 .. i - 1] ++ [True] == map (ar !) [i1 .. i1 + n - 1] | i1 <- [1 .. i - n]] in
cycle $ map fromEnum $ elems ar
bin2dec :: [Int] -> Int
bin2dec = sum . uncurry (zipWith (*)) . first (map (2^) . takeWhile (>=0) . iterate (subtract 1) . subtract 1 . length) . dupe
somebases :: Int -> IO ()
somebases n = let d = take (2^n) $ L.preferOne n in
print (d, bin2dec d, showHex (bin2dec d) "")
main :: IO ()
main = mapM_ somebases [3..6]
各 \(B(2, n)\) が次のように得られる.
([0,0,0,1,1,1,0,1],29,1d)
([0,0,0,0,1,1,1,1,0,1,1,0,0,1,0,1],3941,f65)
([0,0,0,0,0,1,1,1,1,1,0,1,1,1,0,0,1,1,0,1,0,1,1,0,0,0,1,0,1,0,0,1],131913257,7dcd629)
([0,0,0,0,0,0,1,1,1,1,1,1,0,1,1,1,1,0,0,1,1,1,0,1,0,1,1,1,0,0,0,1,1,0,1,1,0,1,0,0,1,1,0,0,1,0,1,1,0,0,0,0,1,0,1,0,1,0,0,0,1,0,0,1],285870213051386505,3f79d71b4cb0a89)
-
本エントリでは Haskell による実装を示しているが, だいぶ以前に C++ で同様の ntz を実装したのであった. この実装は, この Qiita 投稿 の内容と殆ど同じ. C++ では, 簡単なテンプレートメタプログラミングにより, ビット長ごとに必要となるビットマスクや演算を, 同じ関数呼び出しから型ごとに適切に分岐するよう実装できる(Haskell でも, 似たようなことはできる). ↩
-
Abbas Alhakim, “A SIMPLE COMBINATORIAL ALGORITHM FOR DE BRUIJN SEQUENCES” https://www.mimuw.edu.pl/~rytter/TEACHING/TEKSTY/PreferOpposite.pdf 2018-06-21 アクセス. ↩